段智允, 刘方益, 蒋冬先, 王青乐, 栾温熠, 吴颖, 江天, 唐汉, 谭黎杰
中华胸部外科电子杂志 .
2025, 12 (03):
152-161.
目的 探索国内外主流大语言模型(LLMs)在肺癌辅助诊疗中的应用现状和前景。
方法 来自复旦大学附属中山医院的肺癌诊疗多学科团队,结合国内外指南和长期临床实践经验,设计出40个涵盖肺癌基本概念、肺癌筛查、肺癌诊断、肺癌治疗和肺癌病理5个模块的肺癌诊疗相关问题,提问国内外主流LLMs,包括DeepSeek-V3、DeepSeek-R1、豆包、Kimi和GPT-4o,并收集模型的输出结果。随后由两名经验丰富的胸外科医生依据5分类法对回答的准确性和情感支持度进行评分,对比不同模型间的表现差异。
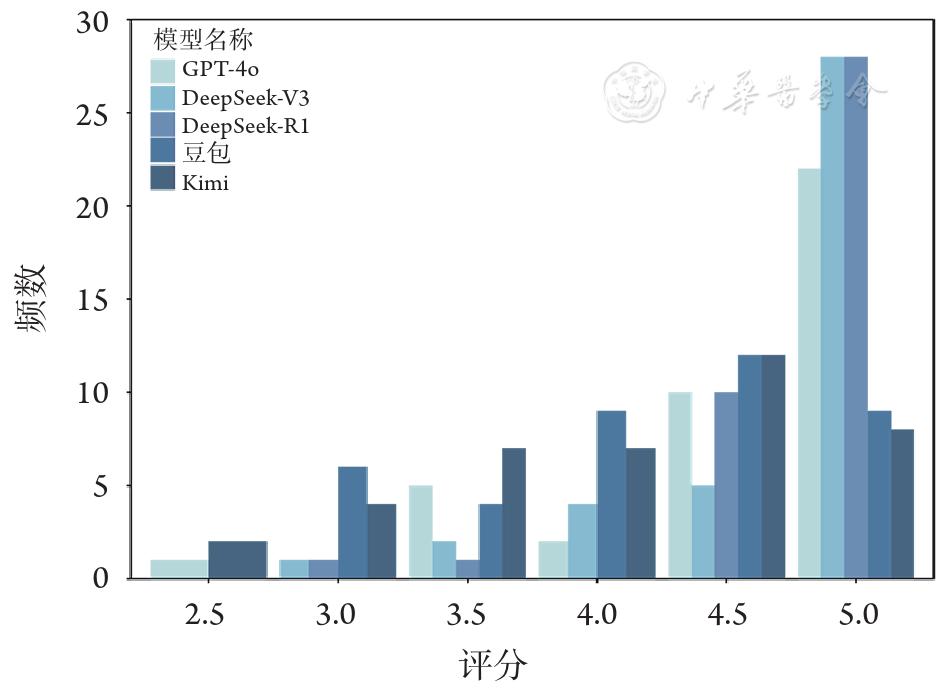
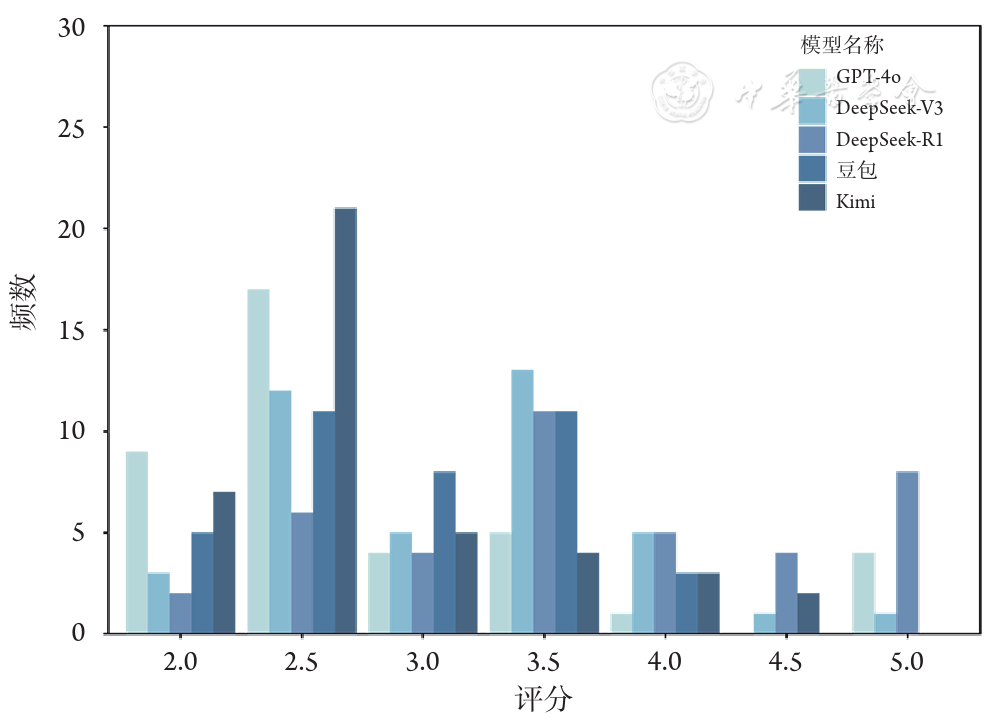
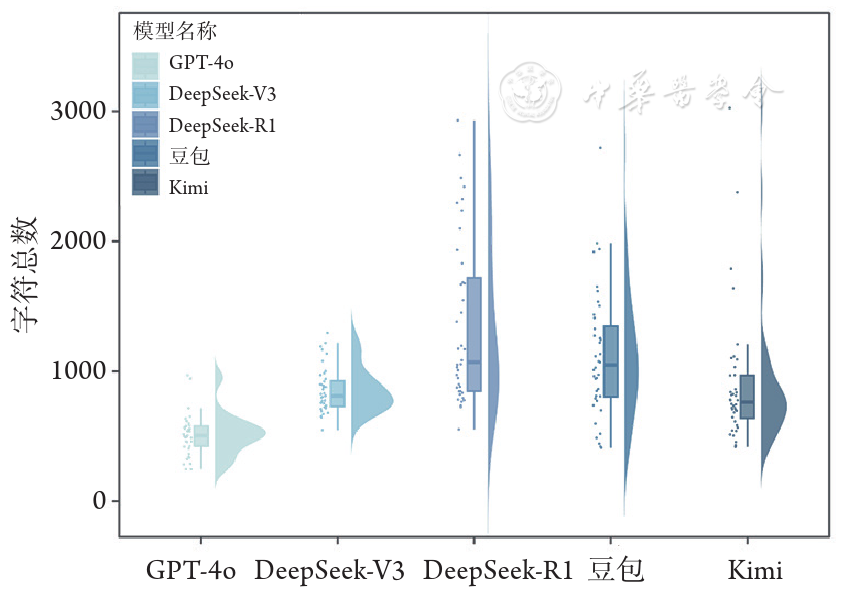
结果 GPT-4o、DeepSeek-V3和DeepSeek-R1表现相似,评分中位数[四分位距(IQR)]为5.00(4.50~5.00),显著优于Kimi[4.25(3.50~4.50)]和豆包[4.50(3.88~4.50)]。亚组分析显示,DeepSeek-R1在基本概念、诊断、治疗和病理多个模块表现出色。DeepSeek-V3整体表现优异,尤其擅长诊断模块。GPT-4o则更擅长筛查模块。情感支持度评估显示,LLMs整体表现显著低于准确性维度,得分中位数集中在3.00附近。其中DeepSeek-R1生成的回答最能让患者感到支持,评分中位数(IQR)为3.50(3.00~4.50)。GPT-4o[2.50(2.50~3.12)]、DeepSeek-V3[3.25(2.50~3.50)]和豆包[3.00(2.50~3.50)]表现相似,优于Kimi[2.50(2.50~3.00)]。亚组分析则显示LLMs在各个模块评分整体偏低,低分占比较高,情感支持不足较为明显。
结论 LLMs在肺癌诊疗领域展现出初步的应用潜力,但在处理复杂临床场景和患者沟通等方面仍存在不足。未来,伴随LLMs不断发展完善,可以预见其在肺癌诊疗领域的广阔应用前景。